Sound constructs often consist of roughly two parts: one synthesizing part (let it call source) feeding into an transformational part (let it call transform). For combining sources with transforms there are two different design strategies (maybe more, but these are the ones I use):
- the source is used as input to transforms (Variant A) or
- utilizing MemoryWriters/Samples or FeedBack loops (Variant B).
The principle of Variant A looks like:
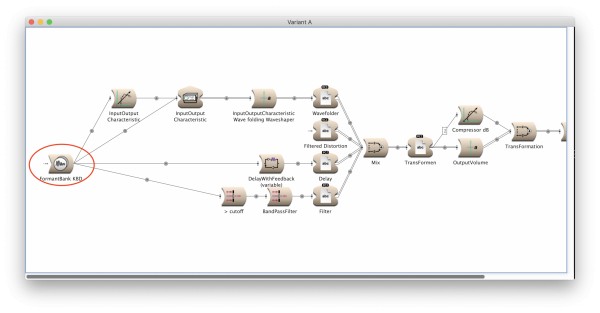
The principle of Variant B looks like:
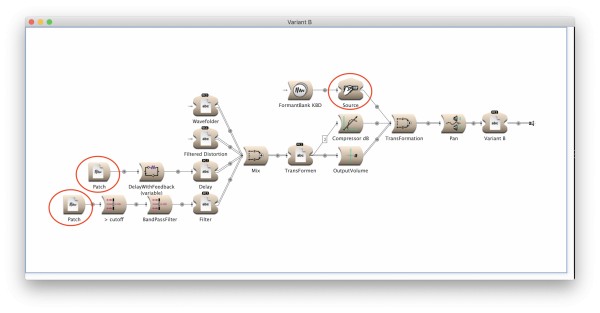
If we compare these two approaches, there is an interesting difference in their properties, mostly related to complexity:
- Variant A has a complexity of 281.191% - 311.186% (approximate)
- Variant B has a complexity of 17.28% - 19.938% (approximate)
This results in the phenomenom that with more and more complex sources and/or transforms Variant A comes very early to an Out-of-Realtime situation (i.e. stopping to work), wheras Variant B fits for bigger sound constructs into Kyma without refusing to work.
I would be very interested to get a bit more background knowledge about the reasons behind; and how to deal with this observation. I guess that the reasons for Variant A are caused by the functional implementation, where nesting means recursion, i.e. a sound part f1(g1(x)) as input of f2(g2(x)) is computed as f2(g2(f1(g1(x)))). In contrast Variant B takes the result of f1(g1(x)) as input stream to f2(g2(x)). But maybe there are other explanations.
Would it be an idea to provide a structural sound within Kyma resulting in a different evaluation strategy without functional recursion, e.g. the input of that sound would be computed separately (on an independent processor) and then feeded as bitstream to the sounds, where it is used as input?
For completeness I attach here the example sounds (simple sounds without artistic relevance, just to show the point):
Design-Variants